
Introduction
LDAP is a ubiquitous source of directory information; the first version of the protocol was codified in 1993. It's commonly used for various applications including managing user/group information for Linux instances, and controlling authentication for VPNs and legacy applications.
Traditionally, a company's LDAP server was run in-house; oftentimes either a part of Microsoft's Active Directory or a deployment of the open source OpenLDAP project. Nowadays, LDAP support is available from SaaS providers; including Foxpass, who was the first cloud LDAP provider to build a multi-tenant, cloud-centric LDAP implementation from the ground up.
A brief primer: LDAP typically has the following primitives: bind, search, compare and add. After creating a TCP connection, applications would first need to bind by sending a username and password. Once bound successfully, the client will issue commands to the LDAP server; typically this is the search command in conjunction with filters. The TCP connection remains until either the client or server disconnects.
LDAP at Foxpass
At Foxpass, our LDAP service is written on top of Twisted, a popular event-based service framework for Python. The service is hosted on AWS's ECS platform, and runs on dozens of containers (nodes). Because LDAP connections are persistent, the cluster must be able to maintain hundreds of thousands of simultaneous TCP sessions.
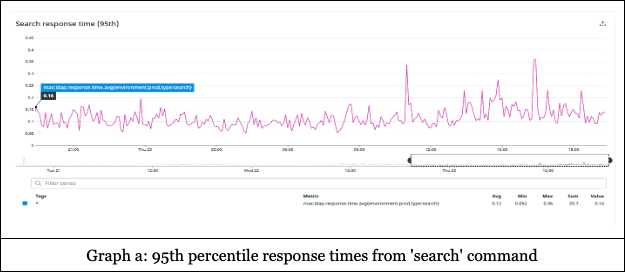
We keep the customers' data in RAM. The reason for this is several-fold. First, the dataset is relatively small, even for large customers. Second, the LDAP query language allows for searching on arbitrary fields (which is important, since Foxpass allows custom fields). This means that a traditional RDBMS system will not be able to build effective indices and we must transform the data into a different in-memory representation. Third, keeping the data in RAM allows for the fastest-possible response time: latencies are typically around 100ms (see graph a).
One drawback with this approach is that of cache invalidation. When a customer's data changes (a user was added or deleted, for example), the LDAP nodes must refresh their data from our main RDBMS. In our previous architecture, this was a relatively expensive operation; when each node refreshes the same company's data it can cause a noticeable spike in LDAP latency and load on the backing-store.
Latency sensitivity challenges
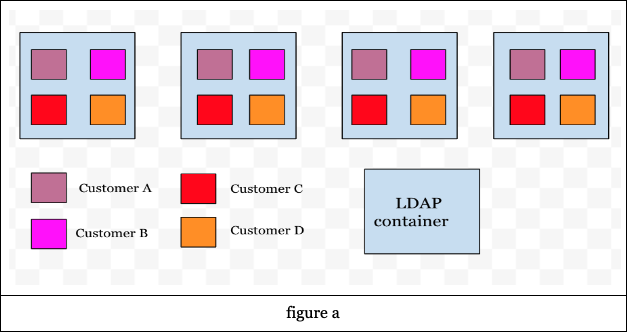
As discussed above, due to the latency requirements, each container stores all customer’s data in-memory (see figure a). The data is fetched on-demand when the request lands on a node (if it's not already present) and then remains for as long as at least one connection from that customer remains.
Since an incoming connection request could land on any container (via the load balancer), the container that fields a query also loads and stores all of the customer's data. Subsequently, the container registers with a redis pubsub service to receive invalidation messages. When an update to the company's data occurs, an invalidate signal is broadcasted and the receiving nodes clear that company's cache of data and goes to the database to re-fetch the company's data. This poses the following challenges to scale our LDAP service as we continuously grew and added new customers into our system:
-
All the data for customer (M) across all the nodes (N) requires a reload on invalidates. Although in practice not every node hosts a connection from every customer, in the worst-case there are MxN calls made to the database to refresh the data. As more customers are added (M), the number of DB fetches can increase by a factor of N. This also meant, so as to not overwhelm the database machines, extra DB reader instances are required to handle the spike in requests.
-
Since all the data across customers (M) is stored in memory across many nodes (N), the memory continues to increase across all the nodes proportional to the number of customers (M). This also means that the container's memory requirements must grow to accommodate all the data in memory, which in-turn increases the overall infrastructure cost.
The above challenges were very clear and got us gravitating towards distributing the customers' data across the nodes instead of replicating all customers' data on every node. This led us to a distributed cache management solution.
Distributed cache management
We introduced an intelligent routing layer in our LDAP service that forwarded requests to the nodes that hosted the customer's data, if the container on which the connection landed did not host the data. To achieve this we narrowed down on the following design requirements for the routing layer:
-
Customers need to be distributed dynamically across the nodes as they are added.
-
Customers' data needs to be distributed dynamically as the nodes shrink, expand and on node failures
-
Ability to increase and decrease the number of partitions for a specific customer so that imbalance in traffic will not overwhelm any single node.
We introduced Apache Helix which distributes the resources across instances. Helix controller is the brain of the helix ecosystem. It makes resource assignment decisions across nodes when nodes or customers are added or removed. We dockerized Apache Helix controller, Rest server and deployed it on ECS. Helix controller depends on Zookeeper to listen to cluster changes. We implemented a reliable way to deploy Zookeeper on ECS. The whole infrastructure of Helix and Zookeeper runs on ECS.
Every LDAP node interacts with the Zookeeper to register themselves to participate in the cluster. Each LDAP instance comes up as a Helix participant that participates in the cluster for customer-to-node assignments by the Helix controller. When a new customer is created on-the-fly by an LDAP node, the number of partitions (each partition representing a node that hosts the data) for that customer is determined based on the number of users. With this integration, our LDAP nodes are aware of events that take place in the cluster i.e. when a new customer is added or when the set of nodes available changes.
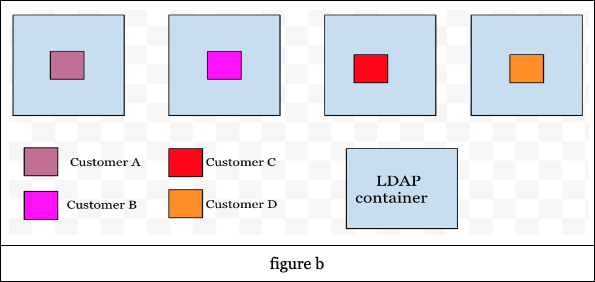
With this cluster awareness, the routing layer in our LDAP service provides the mapping between the nodes and the customers. Every incoming connection will now go through the routing layer to decide on which node the connection has to be routed to. With this the customer's data is assigned to specific nodes (see figure b).
The routing layer hosts a cache that has the route information of customers and the nodes. The routing layer watches for any customer-to-node assignment changes and updates immediately when the changes are detected. In this way, every LDAP node is aware of customer-to-node changes as soon as they happen. With the above cache management solution the scalability challenges mentioned in the Latency sensitivity challenges section were addressed:
-
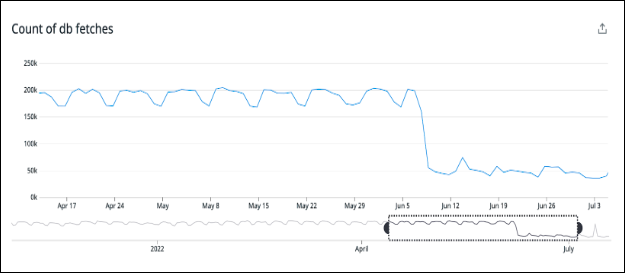
We now have customers distributed across the nodes. Every node will host only a subset of customers and is responsible for fetching only a subset of customers' data upon receiving pubsub invalidates. This significantly reduces the number of reads to the DB, removing the need to add DB reader nodes to handle high volume of DB reads. The LDAP cluster now makes 75% fewer DB reads than it did before.
-
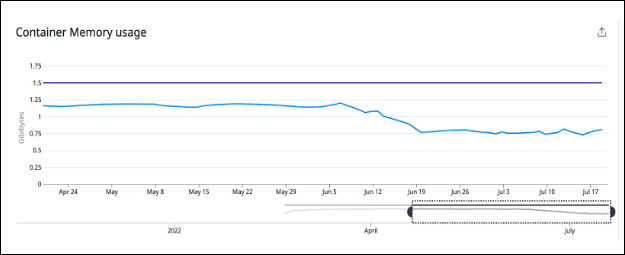
We also have improved memory efficiency because we don’t store all the customer (M) data in memory across all nodes (N). This architecture provides the ability to scale horizontally without increasing the instance size. Every LDAP node now consumes 40% less memory than it did before.
Current challenges
With the above implementation one of the challenges is that nodes receive an unequal number of TCP connections. This distribution imbalance causes more CPU utilization on some nodes (hot nodes) when compared to the others. But the average overall CPU utilization across the nodes still remains the same when compared to before.

.png)



